|
I am a Ph.D. student in ReLER, AAII, University of Technology Sydney, supervised by Yi Yang. My research interests lie in AI safety and visual generation. Before UTS, I was a Research Assistant in Baidu Research co-supervised by Yifan Sun and Yi Yang. Prior to Baidu, I was a Remote Research Intern in Inception Institute of Artificial Intelligence (IIAI) from 2020 to 2021, where I was supervised by Fang Zhao and Shengcai Liao. I gained my bachelor degree from Beihang University in 2021 with Shenyuan Medal (Top 10 Undergraduate). Email / Google Scholar / OpenReview / HuggingFace / Github / Twitter |

|
|
I am currently seeking a research scientist position in industry. If my research aligns with your interests, I would be glad to connect. I am expected to graduate in Spring 2026. |
|
|
|
Video Generation + User. Building three large-scale datasets to improve video generation models by better aligning them with user needs and intent. |
|

|
Wenhao Wang, Yi Yang NeurIPS, 2025 arXiv / Data / bibtex VideoUFO is the first dataset curated in alignment with real-world users’ focused topics for text-to-video generation. Specifically, the dataset comprises over 1.09 million video clips spanning 1,291 topics. |

|
Wenhao Wang, Yi Yang ICCV, 2025 arXiv / Data / Code / bibtex TIP-I2V is the first dataset comprising over 1.70 million unique user-provided text and image prompts for image-to-video generation. It contributes to the development of better and safer image-to-video models. |

|
Wenhao Wang, Yi Yang NeurIPS, 2024 arXiv / Github / Hugging Face / Wisemodel / bibtex / Zhihu / poster ✨ Top6/121,084 in the Hugging Face Dataset Trending List on Mar. 19th 2024. VidProM is the first dataset featuring 1.67 million unique text-to-video prompts and 6.69 million videos generated from 4 different state-of-the-art diffusion models. It inspires many exciting new research areas, such as Text-to-Video Prompt Engineering, Efficient Video Generation, Fake Video Detection, and Video Copy Detection for Diffusion Models. |
|
Diffusion Models + Provenance. Developing provenance methods for diffusion models to trace the origin of generated images and evaluate their similarity to pre-existing images. |
|

|
Wenhao Wang, Yifan Sun, Zongxin Yang, Zhentao Tan, Zhengdong Hu, Yi Yang ICML, 2025 arXiv / Code / Data / bibtex This paper proposes a novel task, origin identification for text-guided image-to-image diffusion models. We propose a simple but generalizable method by utilizing linear-transformed embeddings encoded by the VAE. Theoretically, we prove the existence and generalizability of the required linear transformation. |
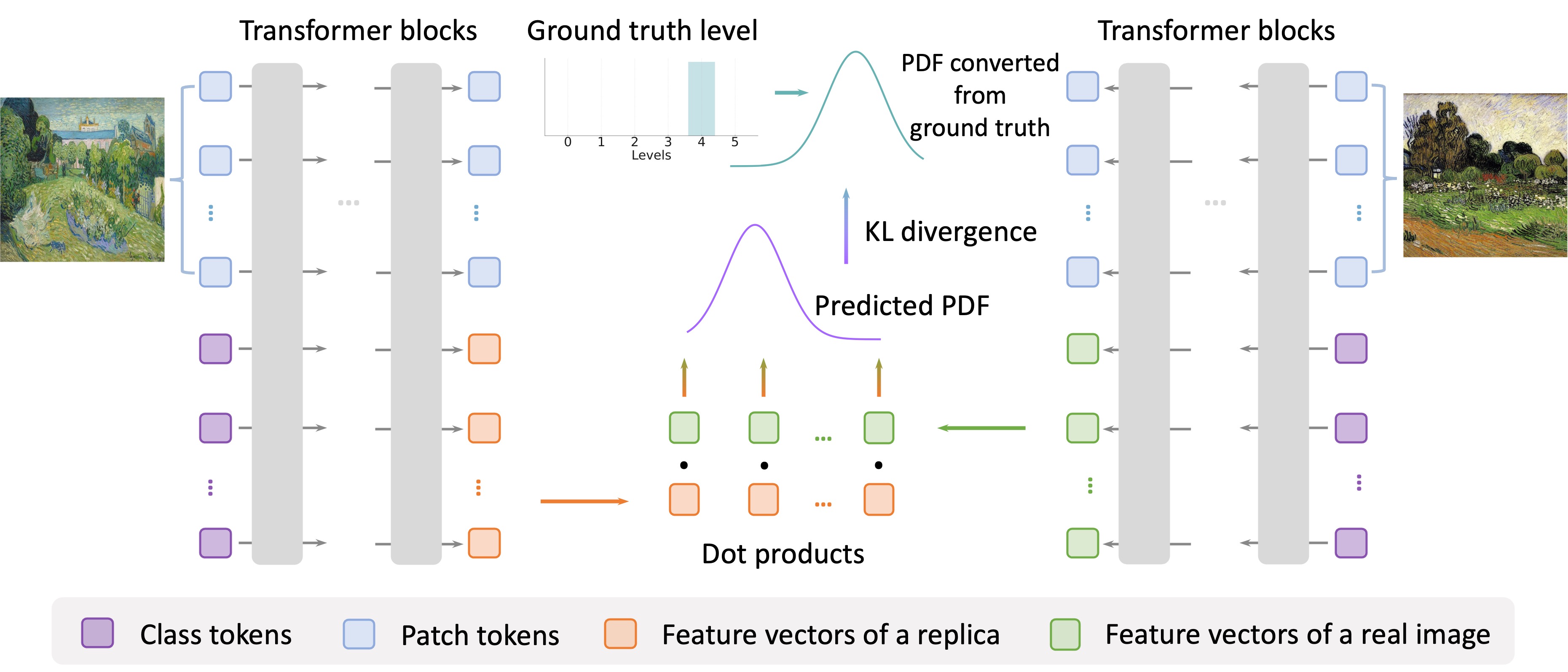
|
Wenhao Wang, Yifan Sun, Zhentao Tan, Yi Yang NeurIPS, 2024 arXiv / Code / Data / bibtex / poster In this paper, we introduce ICDiff, the first Image Copy Detection (ICD) specialized for diffusion-generated replicas. To this end, we construct a Diffusion-Replication (D-Rep) dataset and correspondingly propose a novel deep embedding method. |
|
Wenhao Wang, Yifan Sun, Zongxin Yang, Zhengdong Hu, Zhentao Tan, Yi Yang Arxiv, 2024 arXiv / Project / bibtex In this survey, we provide the first comprehensive review of replication in visual diffusion models, marking a novel contribution to the field by systematically categorizing the existing studies into unveiling, understanding, and mitigating this phenomenon. |
|
Image Copy Detection. Designing image copy detection systems that can efficiently adapt to novel tampering patterns and avoid interference from hard negatives. |
|

|
Wenhao Wang, Yifan Sun, Zhentao Tan, Yi Yang IJCV, 2025 arXiv / Code (ICD) / Code (Style) / Data / bibtex This paper explores in-context learning for image copy detection (ICD), i.e., prompting an ICD model to identify replicated images with new tampering patterns without the need for additional training. To accommodate the “seen → unseen” generalization scenario, we construct the first large-scale pattern dataset named AnyPattern, which has the largest number of tamper patterns (90 for training and 10 for testing) among all the existing ones. |
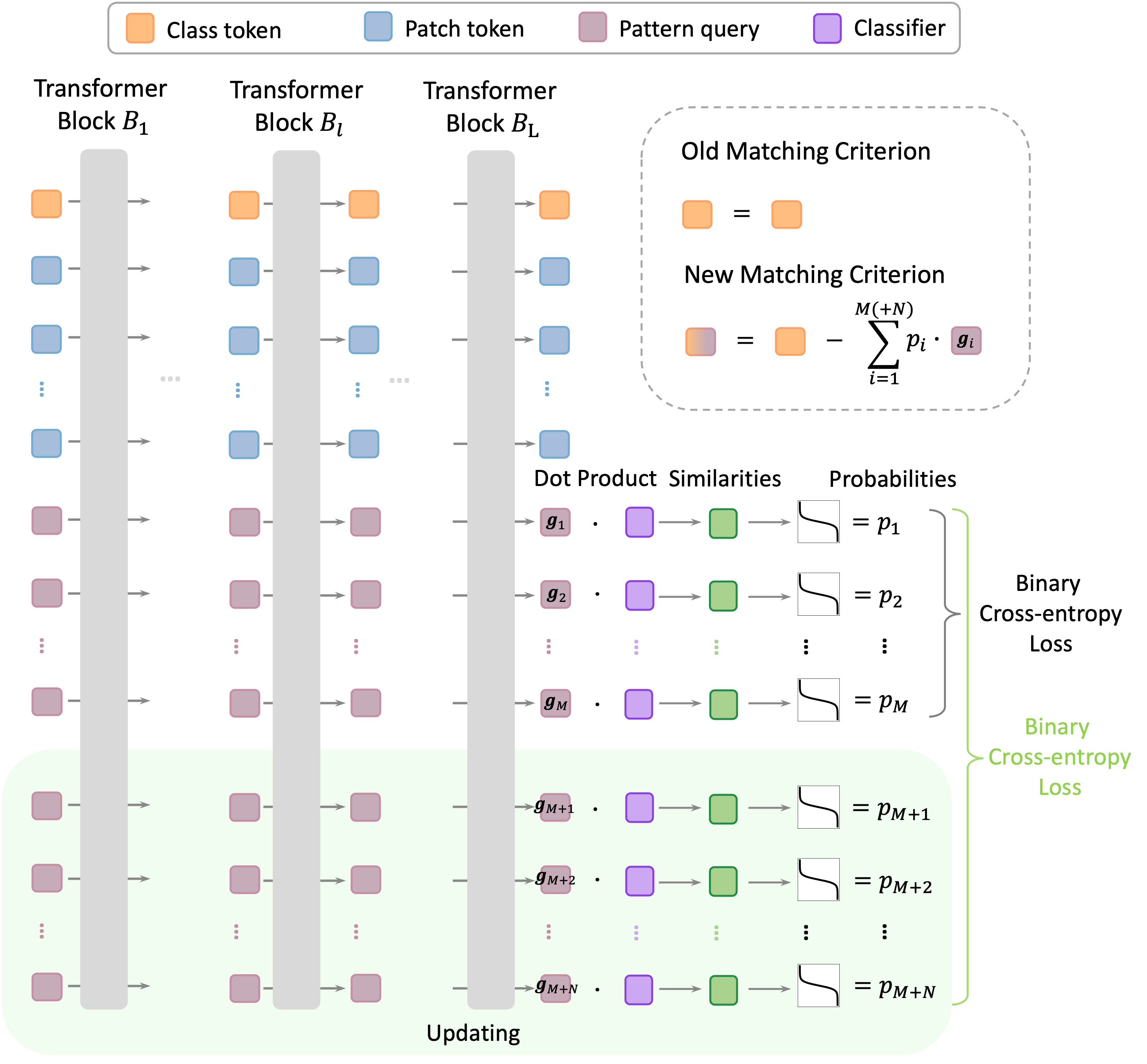
|
Wenhao Wang, Yifan Sun, Yi Yang IJCV, 2024 Code / Data / bibtex This paper proposes a specific open-world visual recognition task, i.e. Pattern-Expandable Image Copy Detection (PE-ICD). To lay the foundation for PE-ICD research, we propose Pattern Stripping (P-Strip), which separates the tamper patterns from a query by decomposing the query feature into a content feature and multiple pattern features. |
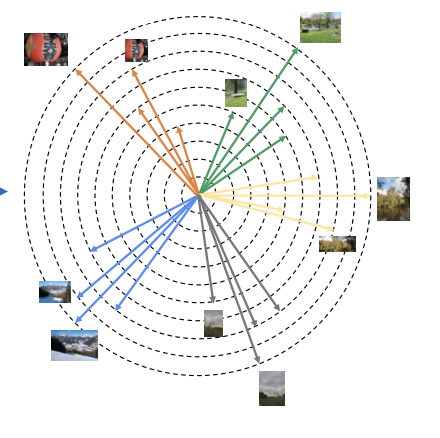
|
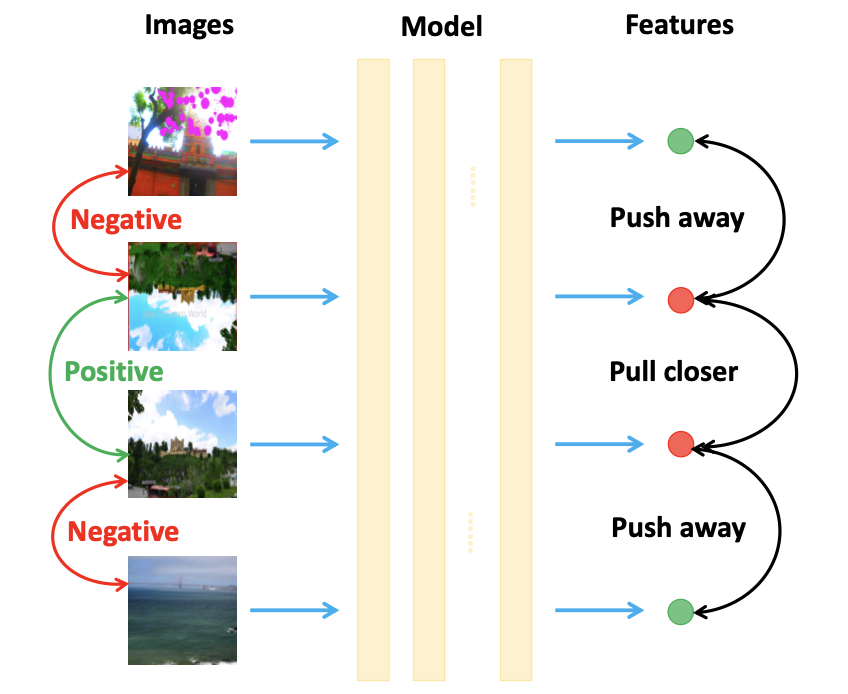
Wenhao Wang, Yifan Sun, Yi Yang AAAI, 2023 (Oral) arXiv / Dataset&Code / bibtex / poster We contribute a new ICD dataset, i.e., Negative-Distractor for Edited Copy (NDEC), with emphasis on the seldom-noticed hard negative problem. We propose a novel Asymmetric-Similarity Learning (ASL) method for ICD. |
|
Fundamental Computer Vision. Conducting research on fundamental computer vision tasks, such as image classification, image retrieval, and object detection. |
|
|
|
Wenhao Wang, Yifan Sun, Wei Li, Yi Yang NeurIPS, 2023 arXiv / Code / bibtex / poster This paper explores a hierarchical prompting mechanism for the hierarchical image classification (HIC) task. Different from prior HIC methods, our hierarchical prompting is the first to explicitly inject ancestor-class information as a tokenized hint that benefits the descendant-class discrimination. |
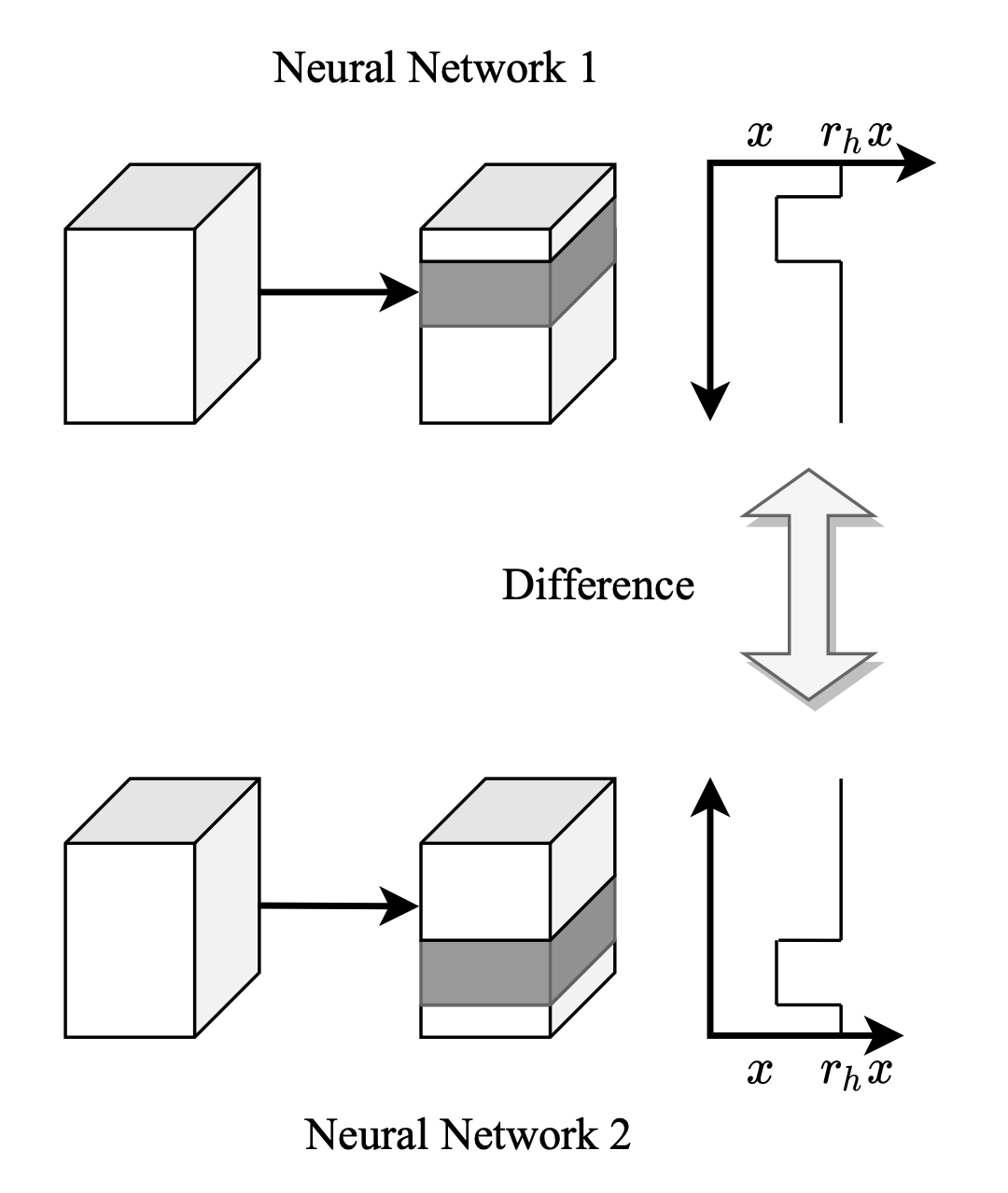
|
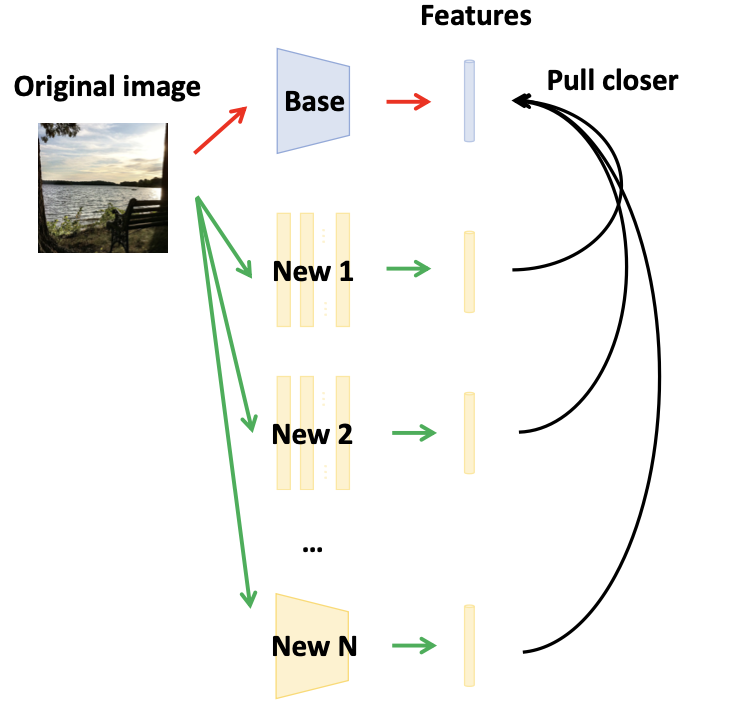
Wenhao Wang, Fang Zhao, Shengcai Liao, Ling Shao TIP, 2022 arXiv / Code / bibtex This paper proposes a novel light-weight module, the Attentive WaveBlock (AWB), which can be integrated into the dual networks of mutual learning to enhance the complementarity. |
|
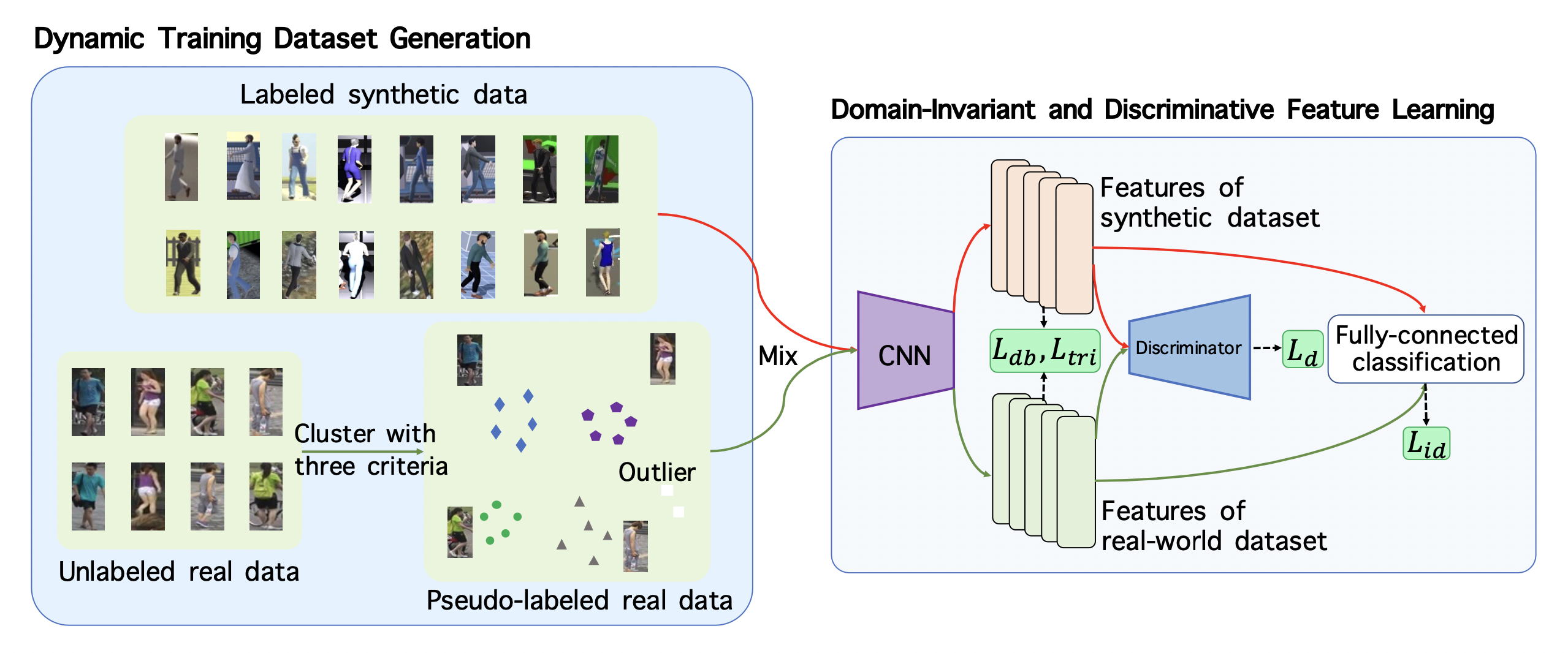
Wenhao Wang, Shengcai Liao, Fang Zhao, Cuicui Kang, Ling Shao BMVC, 2021 arXiv / Code / bibtex We propose a new person re-identification task, i.e. how to use labeled synthetic dataset and unlabeled real-world dataset to train a universal model. A DomainMix framework is introduced to give a basic solution to the task. |
|
|
|
Wenhao Wang, Yifan Sun, Yi Yang CVPR, 2023 (Rank 2) Introduction / Solution / Code / Presentation We propose Feature-Compatible Progressive Learning (FCPL), which trains various models that produce mutually-compatible features. |
|
Wenhao Wang, Yifan Sun, Yi Yang CVPR, 2023 (Rank 2) Introduction / Solution / Code / Presentation We use Temporal Network (TN) to ensemble the features from the descriptor track directly. |
|
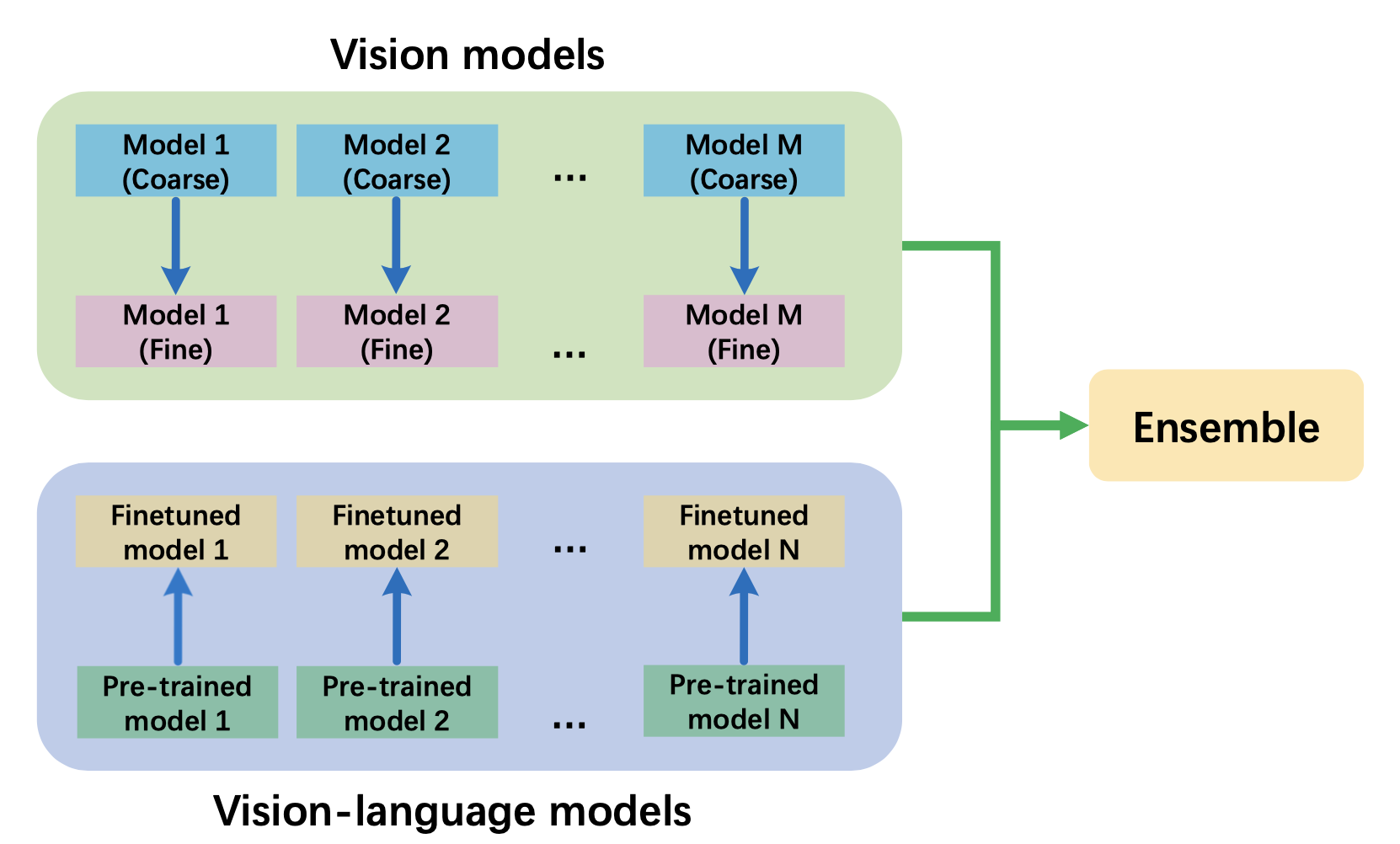
Wenhao Wang, Yifan Sun, Zongxin Yang, Yi Yang CVPR, 2022 (Rank 1) Introduction / Solution / Code / Certificate The paper demonstrates the effectiveness of vision-language models in product retrieval tasks for the first time. |
|
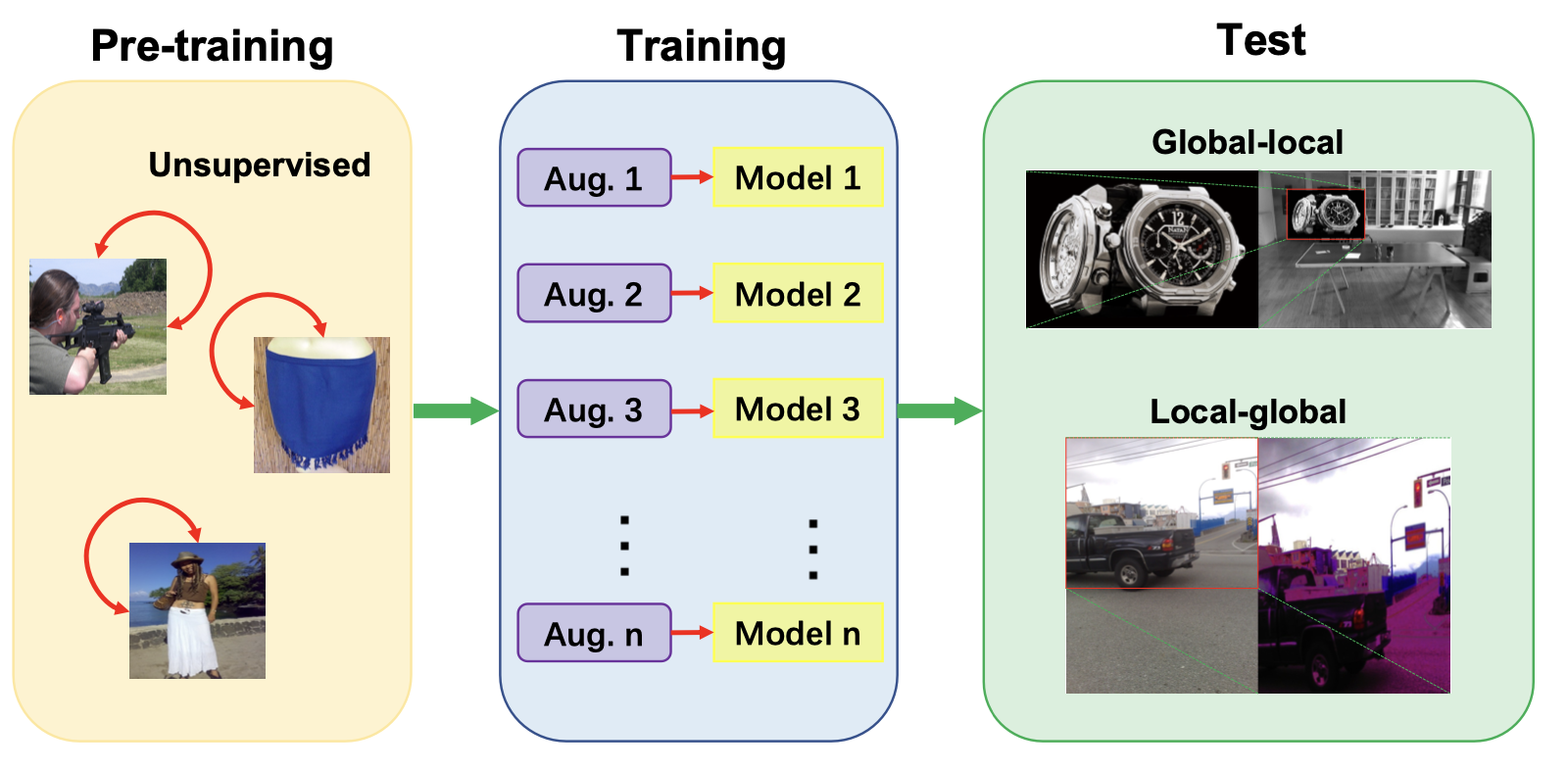
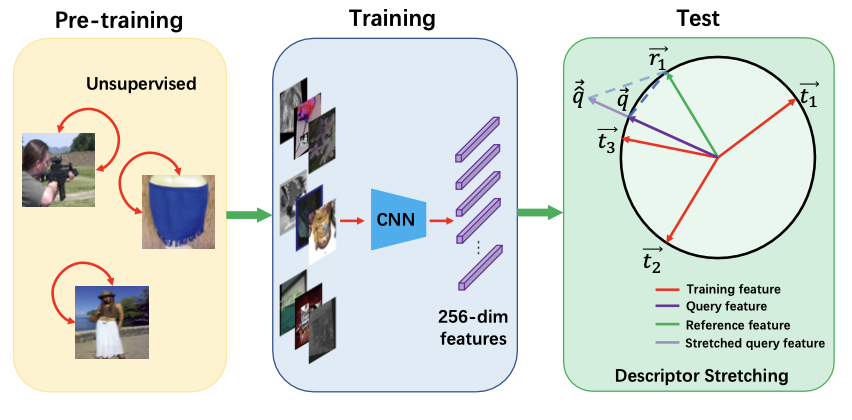
Wenhao Wang, Yifan Sun, Weipu Zhang, Yi Yang NeurIPS, 2021 (Rank 1) Introduction / Solution / Code / Presentation In this paper, a data-driven and local-verification approach is proposed. |
|
Wenhao Wang, Yifan Sun, Weipu Zhang, Yi Yang NeurIPS, 2021 (Rank 3) Introduction / Solution / Code / Presentation In this paper, a bag of tricks and a strong baseline are proposed for image copy detection. |
|
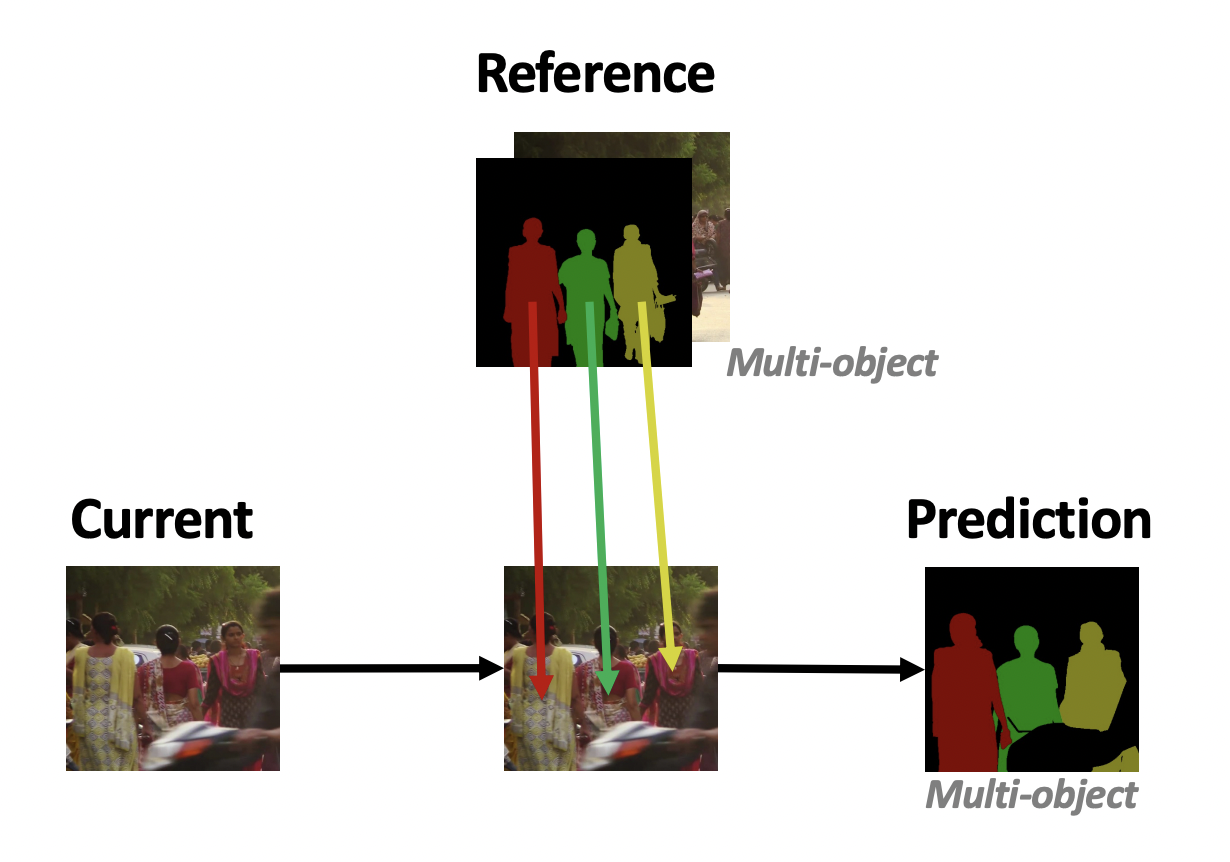
Zongxin Yang, Jian Zhang, Wenhao Wang, etc CVPR, 2021 (Rank 1) Introduction / Solution / Code / Certificate This paper investigates how to realize better and more efficient embedding learning to tackle the semi-supervised video object segmentation under challenging multi-object scenarios. |
|
|
|
Journal Reviewer of Transactions on Pattern Analysis and Machine Intelligence, International Journal of Computer Vision, Transactions on Image Processing, Transactions on Circuits and Systems for Video Technology, Knowledge-Based Systems, Transactions on Intelligent Transportation Systems, IEEE/CAA Journal of Automatica Sinica, Transactions on Big Data, Transactions on Artificial Intelligence, Journal of Visual Communication and Image Representation, and Neural Networks. Conference Reviewer of International Conference on Learning Representations, International Conference on Machine Learning, Conference on Neural Information Processing Systems, International Conference on Computer Vision, Conference on Computer Vision and Pattern Recognition, European Conference on Computer Vision, AAAI Conference on Artificial Intelligence, and ACM Multimedia. |